저작권 안내
- 책 또는 웹사이트의 내용을 복제하여 다른 곳에 게시하는 것을 금지합니다.
- 책 또는 웹사이트의 내용을 발췌, 요약하여 강의 자료, 발표 자료, 블로그 포스팅 등으로 만드는 것을 금지합니다.
CoreOS 사용하기
이재홍 http://www.pyrasis.com 2014.08.02 ~ 2014.09.20
fleet 자동 복구 확인하기
fleet는 노드에 장애가 발생하면 해당 노드에서 실행되던 유닛을 다른 노드에서 실행해줍니다. 이번에는 hello.service 유닛이 실행되는 노드(저는 core-02)에 장애가 발생했다고 가정해보고, 해당노드에서 다음 명령을 실행하여 가상 머신을 종료합니다.
core-02
$ sudo halt
이제 다른 노드에서 서버(머신) 목록을 출력합니다.
core-01
$ fleetctl list-machines
MACHINE IP METADATA
6960c4ce... 172.17.8.103 -
b3318c7b... 172.17.8.101 -
저는 core-02를 종료했기 때문에 core-01(b3318c7b, 172.17.8.101), core-03(6960c4ce, 172.17.8.103)만 표시됩니다.
클러스터의 유닛 목록을 출력합니다.
core-01
$ fleetctl list-units
UNIT DSTATE TMACHINE STATE MACHINE ACTIVE
hello.service launched 6960c4ce.../172.17.8.103 launched 6960c4ce.../172.17.8.103 active
저는 hello.service 유닛이 core-03(6960c4ce, 172.17.8.103)에 다시 실행되었습니다. 각자 상황에 따라 유닛이 실행되는 노드는 달라질 수 있습니다. 이렇게 CoreOS는 fleet을 이용하여 고가용성(High Availability)를 제공합니다.
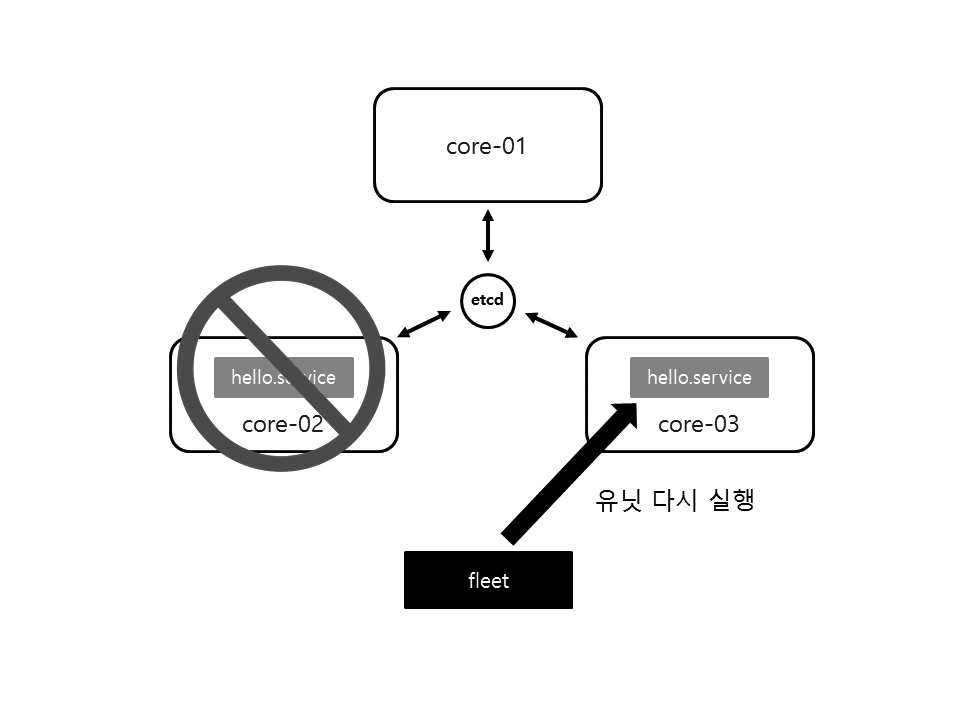 그림 15-23 fleet 유닛 자동 복구
그림 15-23 fleet 유닛 자동 복구
vagrant에서 가상 머신 다시 시작하기
$ sudo vagrant halt -f core-02
$ sudo vagrant up core-02
유닛이 다시 실행되는 것을 확인했으면 유닛(hello.service)을 정지하고, 클러스터에서 삭제합니다.
core-01
$ fleetctl stop hello.service
$ fleetctl destroy hello.service





저작권 안내
이 웹사이트에 게시된 모든 글의 무단 복제 및 도용을 금지합니다.- 블로그, 게시판 등에 퍼가는 것을 금지합니다.
- 비공개 포스트에 퍼가는 것을 금지합니다.
- 글 내용, 그림을 발췌 및 요약하는 것을 금지합니다.
- 링크 및 SNS 공유는 허용합니다.