- 책 또는 웹사이트의 내용을 복제하여 다른 곳에 게시하는 것을 금지합니다.
- 책 또는 웹사이트의 내용을 발췌, 요약하여 강의 자료, 발표 자료, 블로그 포스팅 등으로 만드는 것을 금지합니다.
실전 예제: 웹 크롤러 작성하기
이재홍 http://www.pyrasis.com 2014.12.17 ~ 2015.02.07
지금까지 Go 언어의 기본 문법과 라이브러리 사용 방법에 대해 알아보았습니다. 이제 실전 예제를 통해 Go 언어를 완전히 익혀보겠습니다.
인터넷을 사용하다보면 검색 엔진을 자주 사용하게 됩니다. 검색 엔진은 검색어만 입력하면 그에 맞는 웹 페이지의 링크를 보여줍니다. 여기서 검색 엔진은 어떻게 웹에 있는 정보를 수집할까요? 바로 웹 크롤러라는 프로그램으로 인터넷의 웹 페이지를 수집합니다.
이번에는 Go 언어로 웹 페이지의 정보를 수집하는 웹 크롤러를 만들어보겠습니다. 단 Go 언어를 익히는 것이 목적이므로 구글처럼 검색 엔진에서 사용하는 복잡한 웹 크롤러를 만들기 보다는 특정 사이트의 일부 데이터만 수집하는 간단한 웹 크롤러를 만들어보겠습니다.
예제 웹 크롤러가 수집할 데이터와 수집 방법은 다음과 같습니다.
- 사이트: GitHub(http://github.com)
- 수집 방법: GitHub 사용자의 팔로잉(Following)을 계속 따라가면서 데이터 수집
- class가 gravatar인 요소의 부모에서 href 속성을 수집하여 URL 생성
- URL 형식: https://github.com/id/following
- 수집할 데이터: 사용자 이름
- class가 avatar left이고 태그가 img인 요소에서 alt 속성을 수집하여 사용자 이름을 구함
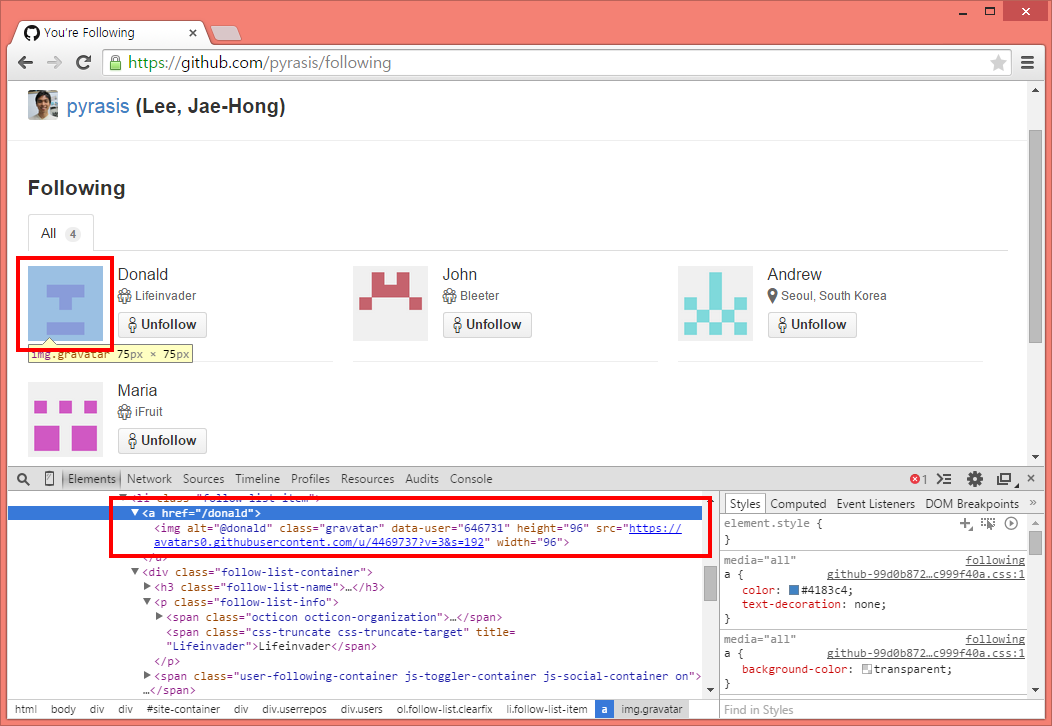 그림 66-1 수집할 URL
그림 66-1 수집할 URL
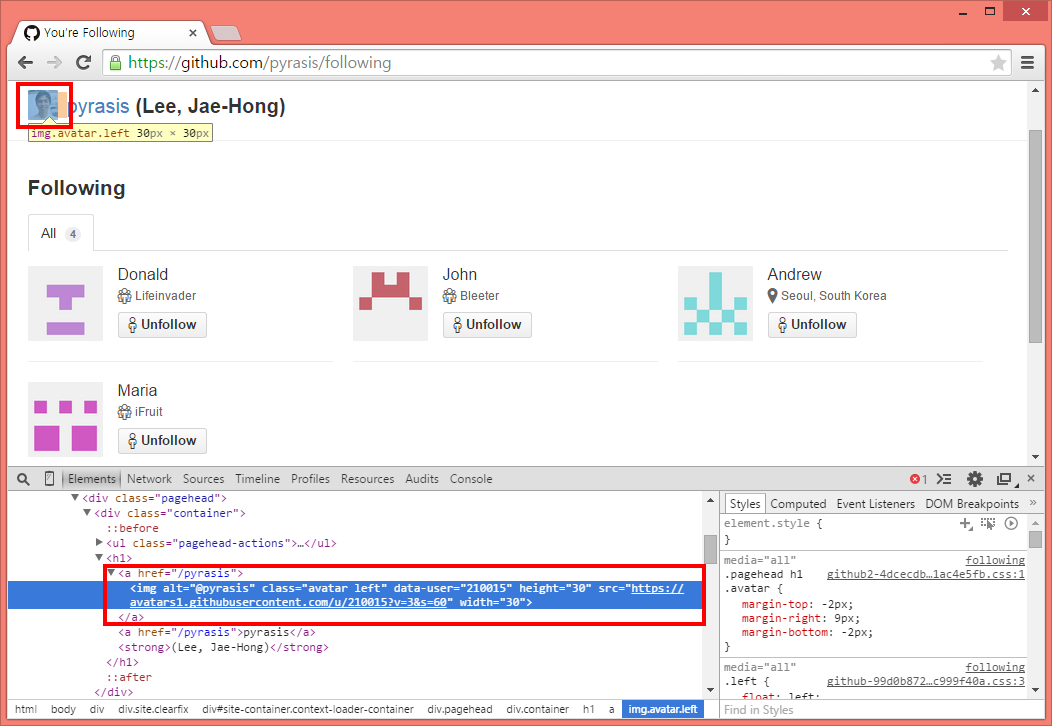 그림 66-2 수집할 사용자 이름
그림 66-2 수집할 사용자 이름
보통 검색 엔진의 웹 크롤러는 웹 페이지에서 나오는 모든 링크를 따라가면서 데이터를 수집합니다. 하지만 여기서는 모든 링크를 따라가지 않고 간단하게 GitHub의 팔로잉 정보만 사용해서 데이터를 수집하겠습니다.
먼저 웹 페이지의 URL에서 데이터를 가져오는 함수를 작성합니다.
package main
import (
"fmt"
"golang.org/x/net/html" // HTML 파싱 해키지
"log"
"net/http"
"runtime"
"sync"
)
...
func fetch(url string) (*html.Node, error) {
res, err := http.Get(url) // URL에서 HTML 데이터를 가져옴
if err != nil {
log.Println(err)
return nil, err
}
doc, err := html.Parse(res.Body) // res.Body를 넣으면 파싱된 데이터가 리턴됨
if err != nil {
log.Println(err)
return nil, err
}
return doc, nil
}
...
http.Get 함수로 URL에서 HTML 데이터를 가져옵니다. 하지만 이 데이터는 URL에 접근했을 때의 상태 값과 텍스트 형식의 HTML 데이터만 있습니다. 텍스트 형식의 HTML을 일일이 처리하려면 매우 불편하므로 golang.org/x/net/html 패키지를 사용하여 파싱합니다.
html.Parse 함수에 HTML 텍스트가 들어있는 res.Body를 넣으면 html.Node가 리턴됩니다. 그리고 이 html.Node로 각 HTML 요소를 탐색하거나 값을 가져올 수 있습니다.
다음은 html.Node에서 팔로잉 정보를 검색하여 GitHub 사용자 이름을 출력하고, 팔로잉 URL을 리턴하는 함수입니다.
...
func parseFollowing(doc *html.Node) []string {
var urls = make([]string, 0)
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "img" { // img 태그
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "avatar left" { // class가 avatar left인 요소
for _, a := range n.Attr {
if a.Key == "alt" {
fmt.Println(a.Val) // 사용자 이름 출력
break
}
}
}
if a.Key == "class" && a.Val == "gravatar" { // class가 gravatar인 요소
user := n.Parent.Attr[0].Val // 부모 요소의 첫 번째 속성(href)
// 사용자 이름으로 팔로잉 URL 조합
urls = append(urls, "https://github.com"+user+"/following")
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
}
f(doc)
return urls
}
...
HTML은 부모(Parent)-자식(Child), 형제(Sibling)와 같은 계층 구조로 되어있으므로 재귀호출을 사용해야 합니다. 따라서 var f func(*html.Node)처럼 변수를 선언하고 이 변수에 HTML을 처리하는 함수를 정의하여 대입합니다. 그리고 다음과 같이 자식과 형제를 모두 탐색합니다.
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
HTML을 처리하려면 해당 웹 페이지의 HTML 구조를 파악해야 합니다. 다음은 GitHub 팔로잉 페이지 HTML의 일부입니다.
... (생략)
<a href="/pyrasis">
<img alt="Jae-Hong Lee" class="avatar left" data-user="210015" height="30" src="https://avatars1.githubusercontent.com/u/210015?v=3&s=60" width="30" />
</a>
... (생략)
이 <img> 태그는 현재 팔로잉 페이지의 사용자 프로필 이미지입니다. 따라서 다음과 같이 html.ElementNode이면서 img인 요소를 탐색합니다. 그리고 class가 avatar left이면 찾고자하는 사용자 프로필 이미지입니다. 사용자 이름은 <img> 태그의 alt 속성에서 얻습니다.
... (생략)
if n.Type == html.ElementNode && n.Data == "img" { // img 태그
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "avatar left" { // class가 avatar left인 요소
for _, a := range n.Attr {
if a.Key == "alt" {
fmt.Println(a.Val) // 사용자 이름 출력
break
}
}
... (생략)
팔로잉 페이지에는 해당 사용자가 팔로잉하는 다른 사용자가 표시될 것입니다. 여러 태그들 중에서 팔로잉한 사용자의 프로필 이미지 <img> 태그에서 해당 사용자의 URL을 얻습니다.
... (생략)
<a href="/donald">
<img alt="Donald" class="gravatar" data-user="646731" height="96" src="https://avatars0.githubusercontent.com/u/4469737?v=3&s=192" width="96" /></a>
<a href="/john">
<img alt="John" class="gravatar" data-user="456218" height="96" src="https://avatars0.githubusercontent.com/u/4469736?v=3&s=192" width="96" /></a>
... (생략)
여기서는 class가 gravatar인 것을 찾고 img 태그의 부모 태그 <a>를 찾아서 링크를 구합니다. <a> 태그에는 완전한 형태의 URL이 들어있지 않으므로 "https://github.com"+user+"/following"처럼 앞 뒤에 GitHub 주소와 following 문자열을 붙여줍니다.
if a.Key == "class" && a.Val == "gravatar" { // class가 gravatar인 요소
user := n.Parent.Attr[0].Val // 부모 요소의 첫 번째 속성(href)
// 사용자 이름으로 팔로잉 URL 조합
urls = append(urls, "https://github.com"+user+"/following")
break
}
팔로잉 URL을 구할 때마다 urls 슬라이스에 추가합니다. 그리고 탐색이 끝난 뒤 urls는 리턴합니다.
HTML 파싱 라이브러리
이번 예제에서는 HTML을 파싱할 때 Go 언어에서 제공하는 golang.org/x/net/html 패키지를 사용했습니다. 하지만 GitHub 및 여러 사이트를 둘러보면 좀 더 간편한 HTML 파싱 라이브러리가 많이 나와 있습니다. 다른 라이브러리를 사용하여 파싱하는 부분은 여러분들이 직접 실습해보길 바랍니다.
이제 URL 처리 부분입니다. 이미 처리한 URL은 다시 처리할 필요가 없으므로 중복 URL을 판별할 변수를 선언합니다.
package main
import (
"fmt"
"golang.org/x/net/html" // HTML 파싱 해키지
"log"
"net/http"
"runtime"
"sync"
)
var fetched = struct {
m map[string]error // 중복 검사를 위한 URL과 에러 값 저장
sync.Mutex
}{m: make(map[string]error)} // 변수를 선언하면서 이름이 없는 구조체를 정의하고
// 초깃값을 생성하여 대입
...
매우 축약된 형태의 문법입니다. fetched 변수를 선언하면서 이름이 없는 구조체를 정의하고, 구조체의 초깃값을 생성하여 바로 대입합니다. 필드에는 URL과 에러 값을 저장할 맵이 있고 sync.Mutex는 임베딩되어 있습니다. 이렇게 하면 fetched 변수 자체가 sync.Mutex 기능을 가지게 되므로 **fetched.Lock()**처럼 뮤텍스 함수를 바로 사용할 수 있습니다. fetched 변수의 맵은 여러 고루틴에서 데이터를 조회하고, 넣게 되므로 반드시 뮤텍스로 보호해줍니다.
다음은 URL에서 HTML을 가져온 뒤 사용자 이름을 수집하고, 팔로잉 URL 구해서 재귀호출로 계속 탐색하는 함수입니다.
...
func crawl(url string) {
fetched.Lock() // 맵은 뮤텍스로 보호
if _, ok := fetched.m[url]; ok { // URL 중복 처리 여부를 검사
fetched.Unlock()
return
}
fetched.Unlock()
doc, err := fetch(url) // URL에서 파싱된 HTML 데이터를 가져옴
fetched.Lock()
fetched.m[url] = err // 가져온 URL은 맵에 URL과 에러 값 저장
fetched.Unlock()
urls := parseFollowing(doc) // 사용자 정보 출력, 팔로잉 URL을 구함
done := make(chan bool)
for _, u := range urls { // URL 개수만큼
go func(url string) { // 고루틴 생성
crawl(url) // 재귀호출
done <- true
}(u)
}
for i := 0; i < len(urls); i++ {
<-done // 고루틴이 모두 실행될 때까지 대기
}
}
...
fetch 함수로 URL의 데이터를 가져온 뒤 URL은 fetched 변수의 맵에 저장해놓고, 다음 번 호출 때 같은 URL을 가져오는지 검사합니다. fetched 변수의 맵을 사용할 때는 반드시 뮤텍스 함수로 데이터를 보호해줍니다.
parseFollowing 함수로 사용자 정보를 출력합니다. 그리고 팔로잉 URL을 구했으면 URL 개수만큼 고루틴을 생성하여 다시 crawl 함수를 호출합니다. 그리고 다음과 같이 채널 done 사용하여 고루틴이 모두 실행될 때까지 기다립니다.
for i := 0; i < len(urls); i++ {
<-done // 고루틴이 모두 실행될 때까지 대기
}
이제 메인 함수에서 CPU 코어를 모두 사용하도록 설정하고 crawl 함수를 실행합니다. 최초 시작 URL은 저의 GitHub 팔로잉 페이지입니다.
...
func main() {
numCPUs := runtime.NumCPU()
runtime.GOMAXPROCS(numCPUs) // CPU를 모두 사용하도록 설정
crawl("https://github.com/pyrasis/following") // 크롤링 시작
}
다은은 전체 소스 코드입니다.
package main
import (
"fmt"
"golang.org/x/net/html" // HTML 파싱 해키지
"log"
"net/http"
"runtime"
"sync"
)
var fetched = struct {
m map[string]error // 중복 검사를 위한 URL과 에러 값 저장
sync.Mutex
}{m: make(map[string]error)} // 변수를 선언하면서 이름이 없는 구조체를 정의하고 초깃값을 생성하여 대입
func fetch(url string) (*html.Node, error) {
res, err := http.Get(url) // URL에서 HTML 데이터를 가져옴
if err != nil {
log.Println(err)
return nil, err
}
doc, err := html.Parse(res.Body) // res.Body를 넣으면 파싱된 데이터가 리턴됨
if err != nil {
log.Println(err)
return nil, err
}
return doc, nil
}
func parseFollowing(doc *html.Node) []string {
var urls = make([]string, 0)
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "img" { // img 태그
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "avatar left" { // class가 avatar left인 요소
for _, a := range n.Attr {
if a.Key == "alt" {
fmt.Println(a.Val) // 사용자 이름 출력
break
}
}
}
if a.Key == "class" && a.Val == "gravatar" { // class가 gravatar인 요소
user := n.Parent.Attr[0].Val // 부모 요소의 첫 번째 속성(href)
// 사용자 이름으로 팔로잉 URL 조합
urls = append(urls, "https://github.com"+user+"/following")
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
}
f(doc)
return urls
}
func crawl(url string) {
fetched.Lock() // 맵은 뮤텍스로 보호
if _, ok := fetched.m[url]; ok { // URL 중복 처리 여부를 검사
fetched.Unlock()
return
}
fetched.Unlock()
doc, err := fetch(url) // URL에서 파싱된 HTML 데이터를 가져옴
fetched.Lock()
fetched.m[url] = err // 가져온 URL은 맵에 URL과 에러 값 저장
fetched.Unlock()
urls := parseFollowing(doc) // 사용자 정보 출력, 팔로잉 URL을 구함
done := make(chan bool)
for _, u := range urls { // URL 개수만큼
go func(url string) { // 고루틴 생성
crawl(url) // 재귀호출
done <- true
}(u)
}
for i := 0; i < len(urls); i++ {
<-done // 고루틴이 모두 실행될 때까지 대기
}
}
func main() {
numCPUs := runtime.NumCPU()
runtime.GOMAXPROCS(numCPUs) // 모든 CPU를 사용하도록 설정
crawl("https://github.com/pyrasis/following") // 크롤링 시작
}
이제 소스 파일을 컴파일하여 실행해봅니다. golang.org/x/net/html 패키지는 인터넷에서 받아와야하므로 go get 명령을 먼저 실행한 뒤 go build 명령으로 컴파일합니다.
go get
go build
실행을 해보면 이름이 출력되다가 다음과 같이 "dial tcp ... too many open files" 또는 "TLS handshake timeout" 런타임 에러가 발생합니다.
Donald
John
2015/01/30 09:37:41 Get https://github.com/maria/following: dial tcp 192.30.252.128:443: too many open files
panic: runtime error: invalid memory address or nil pointer dereference
[signal 0xb code=0x1 addr=0x28 pc=0x4012a1]
goroutine 1962 [running]:
runtime.panic(0x617aa0, 0x8f1028)
/usr/lib/go/src/pkg/runtime/panic.c:266 +0xb6
main.func·001(0x0)
/home/pyrasis/hello_project/src/crawler/crawler.go:38 +0x41
... (생략)
재귀호출로 팔로잉 URL을 따라가면서 데이터를 수집하므로 몇 단계만 거치면 crawl 함수를 실행하는 고루틴이 엄청나게 불어납니다. 그래서 짧은 시간 동안 동시에 많은 수의 URL에 접근하게 되므로 에러가 발생할 수 밖에 없습니다(운영체제는 과도하게 리소스를 사용하면 에러를 발생시킵니다). 하지만 에러를 피하겠다고 URL을 하나씩 실행한다면 데이터 수집에 시간이 너무 오래 걸리게 됩니다.
많은 URL을 동시에 처리하면서 에러를 발생시키지 않으려면 다른 방식이 필요합니다.





저작권 안내
이 웹사이트에 게시된 모든 글의 무단 복제 및 도용을 금지합니다.- 블로그, 게시판 등에 퍼가는 것을 금지합니다.
- 비공개 포스트에 퍼가는 것을 금지합니다.
- 글 내용, 그림을 발췌 및 요약하는 것을 금지합니다.
- 링크 및 SNS 공유는 허용합니다.