- 책 또는 웹사이트의 내용을 복제하여 다른 곳에 게시하는 것을 금지합니다.
- 책 또는 웹사이트의 내용을 발췌, 요약하여 강의 자료, 발표 자료, 블로그 포스팅 등으로 만드는 것을 금지합니다.
실전 예제: 웹 크롤러 작성하기
이재홍 http://www.pyrasis.com 2014.12.17 ~ 2015.02.07
채널을 이용한 파이프라인 패턴 활용하기
앞에서 재귀호출로 크롤링을 했다면 이번에는 채널을 이용하여 파이프라인 방식으로 크롤링을 해보겠습니다.
파이프라인이란 대표적인 병렬처리 방법이며 동시에 실행되는 작업의 개수를 제한하여 주어진 작업을 처리합니다. 보통 작업 큐(Work Queue), 작업 풀(Work Pool) 등으로 불리기도 하는데 모두 개념은 비슷합니다.
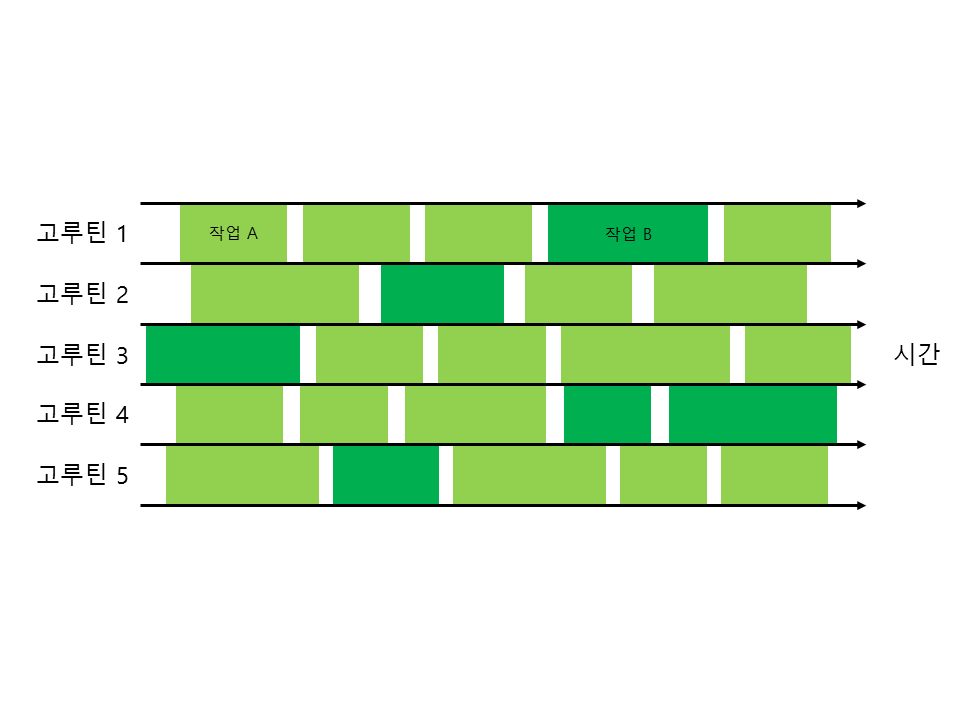 그림 66-3 파이프라인 패턴
그림 66-3 파이프라인 패턴
그림 66-3과 같이 다섯 개의 고루틴에서 작업을 동시에 처리합니다. 마치 여러 개의 파이프(관)에 물을 흘려보내는 것과 비슷하다고 하여 파이프라인이라고 부릅니다. 파이프가 하나라면 흘려보내는 물의 양이 적을 것이고, 파이프가 없다면 흘려보내는 물의 양을 조절할 수 없을 것입니다. 마찬가지로 프로그램에서도 일정한 개수의 고루틴(스레드)으로 동시에 작업을 실행하여 효율적으로 데이터를 처리합니다.
파이프라인 방식으로 크롤링을 처리하면 URL이 수천 개가 쌓여있어도 일정한 개수만큼 URL에 접근합니다. 따라서 운영체제 및 네트워크 리소스를 과도하게 사용하지 않으므로 런타임 에러 없이 원활하게 크롤링 작업을 처리할 수 있습니다.
먼저 웹 크롤러를 파이프라인 방식으로 개선하기 전에 간단하게 파이프라인 패턴으로 문자열을 출력해보겠습니다.
package main
import (
"fmt"
"sync"
"time"
)
// 실제 작업을 처리하는 worker 함수
func worker(n int, done <-chan struct{}, jobs <-chan int, c chan<- string) {
for j := range jobs { // 작업 요청 채널에서 값을 가져와서 실행
select {
case c <- fmt.Sprintf("Worker: %d, Job: %d", n, j):
case <-done: // 채널 done이 닫히면 worker 함수를 빠져나옴
return
}
}
}
func main() {
jobs := make(chan int) // 작업을 요청할 채널
done := make(chan struct{}) // 작업 고루틴에 정지 신호를 보낼 채널
c := make(chan string) // 결괏값을 저장할 채널
var wg sync.WaitGroup
const numWorkers = 5
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ { // 작업을 처리할 고루틴을 5개 생성
go func(n int) {
worker(n, done, jobs, c)
wg.Done()
}(i)
}
go func() {
wg.Wait() // 고루틴이 끝날 때까지 대기
close(c) // 대기가 끝나면 결괏값 채널을 닫음
}()
go func() {
for i := 0; i < 10; i++ { // 작업 요청을 10개 생성하여
jobs <- i // jobs 채널에 보냄
time.Sleep(10 * time.Millisecond)
}
close(done) // 채널을 닫아서 모든 worker 고루틴 정지
close(jobs) // worker 함수의 range 대기도 종료
}()
for r := range c { // 결과 채널에 값이 들어올 때까지 대기한 뒤 값을 가져옴
fmt.Println(r) // 결괏값 출력
}
}
파이프라인 패턴에는 작업을 요청할 채널, 작업 고루틴에 정지 신호를 보낼 채널, 결괏값을 저장할 채널 이렇게 3개가 필요합니다.
jobs := make(chan int) // 작업을 요청할 채널
done := make(chan struct{}) // 작업 고루틴에 정지 신호를 보낼 채널
c := make(chan string) // 결괏값을 저장할 채널
작업을 요청할 채널과 결괏값을 저장할 채널은 원하는 자료형으로 생성하면 됩니다. 정지 신호를 보낼 채널은 특별히 값을 보내지 않고 닫기만 할 것이므로 struct{}처럼 빈 구조체로 생성합니다.
이제 작업을 처리할 고루틴을 5개 생성합니다. 이 고루틴이 파이프라인의 파이프라 할 수 있습니다.
var wg sync.WaitGroup
const numWorkers = 5
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ { // 작업을 처리할 고루틴을 5개 생성
go func(n int) {
worker(n, done, jobs, c)
wg.Done()
}(i)
}
sync.WaitGroup을 사용하여 고루틴이 끝날 때 까지 대기합니다. 대기가 끝나면 결괏값 채널 c를 닫습니다. 여기서는 대기할 때 wg.Wait 함수를 고루틴으로 실행합니다. wg.Wait 함수를 main 함수에서 바로 실행하면 그 상태에서 대기하기 때문에 결과 채널에서 값을 받는 부분이 실행되지 않습니다(결괏값 채널에서 값을 받는 부분을 고루틴으로 실행해도 됩니다).
실제 작업을 처리하는 worker 함수에서는 for range 반복문으로 작업 요청 채널에서 값을 가져와서 실행합니다.
// 실제 작업을 처리하는 worker 함수
func worker(n int, done <-chan struct{}, jobs <-chan int, c chan<- string) {
for j := range jobs { // 작업 요청 채널에서 값을 가져와서 실행
select {
case c <- fmt.Sprintf("Worker: %d, Job: %d", n, j):
case <-done: // 채널 done이 닫히면 worker 함수를 빠져나옴
return
}
}
}
range는 채널이 비어있으면 계속 대기하며 채널에 값이 들어오는 즉시 실행됩니다. 따라서 다른 곳에서 작업 요청 채널 jobs에 값을 보낼 때마다 값을 꺼내서 실행합니다.
select case를 사용하여 매 반복마다 결괏값 채널 c에 값을 보내거나 고루틴 채널이 닫히는지 확인합니다. 여기서 고루틴 정지 신호 채널 done이 닫히면 worker 함수를 빠져나옵니다.
작업 요청을 10개 생성하여 jobs 채널에 보냅니다. 작업 요청을 다 보냈으면 done 채널을 닫아서 모든 worker 고루틴을 종료시킵니다. 그리고 작업 요청 채널 jobs도 닫아서 worker 함수의 range 대기도 종료시킵니다.
go func() {
for i := 0; i < 10; i++ { // 작업 요청을 10개 생성하여
jobs <- i // jobs 채널에 보냄
time.Sleep(10 * time.Millisecond)
}
close(done) // 채널을 닫아서 모든 worker 고루틴 정지
close(jobs) // worker 함수의 range 대기도 종료
}()
메인 함수에서 결괏값 채널 c에 값이 들어올 때까지 대기합니다. 그리고 채널에 값이 들어오면 값을 출력합니다.
for r := range c { // 결과 채널에 값이 들어올 때까지 대기한 뒤 값을 가져옴
fmt.Println(r) // 결괏값 출력
}
소스 파일을 컴파일하여 실행해보면 worker 고루틴 5개에서 균등하게 작업을 처리하는 것을 볼 수 있습니다(runtime.GOMAXPROCS 함수로 모든 CPU 코어를 사용하도록 설정한다면 출력 순서는 조금 달라질 수 있습니다. 하지만 파이프라인 패턴의 기능에는 변함이 없습니다).
Worker: 0, Job: 0
Worker: 1, Job: 1
Worker: 2, Job: 2
Worker: 3, Job: 3
Worker: 4, Job: 4
Worker: 0, Job: 5
Worker: 1, Job: 6
Worker: 2, Job: 7
Worker: 3, Job: 8
Worker: 4, Job: 9
이제 앞에서 만든 GitHub 팔로잉 크롤러를 파이프라인 패턴으로 다시 작성해보겠습니다. 먼저 결괏값을 저장할 구조체를 정의합니다. 여기서는 가져온 URL과 사용자 이름만 저장합니다.
type result struct { // 결괏값을 저장할 구조체
url string // 가져온 URL
name string // 사용자 이름
}
메인 함수에서 작업을 요청할 채널, 작업 고루틴에 정지 신호를 보낼 채널, 결괏값을 저장할 채널을 생성합니다.
...
func main() {
...
urls := make(chan string) // 작업을 요청할 채널
done := make(chan struct{}) // 작업 고루틴에 정지 신호를 보낼 채널
c := make(chan result) // 결괏값을 저장할 채널
...
}
이번 크롤링 예제에서 작업의 단위는 URL입니다. 그러므로 작업 요청 채널에 URL을 보낼 수 있도록 문자열 타입으로 생성합니다.
작업을 처리할 고루틴을 10개 생성하고, sync.WaitGroup을 사용하여 고루틴이 끝날 때까지 대기합니다.
...
func main() {
...
var wg sync.WaitGroup
const numWorkers = 10
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ { // 작업을 처리할 고루틴을 10개 생성
go func() {
worker(done, urls, c)
wg.Done()
}()
}
go func() {
wg.Wait() // 고루틴이 끝날 때까지 대기
close(c) // 대기가 끝나면 결괏값 채널을 닫음
}()
...
}
실제 작업을 처리하는 worker 함수에서는 for range 반복문으로 urls 채널에서 URL을 가져와서 처리합니다.
// 실제 작업을 처리하는 worker 함수
func worker(done <-chan struct{}, urls chan string, c chan<- result) {
for url := range urls { // urls 채널에서 URL을 가져옴
select {
case <-done: // 채널이 닫히면 worker 함수를 빠져나옴
return
default:
crawl(url, urls, c) // URL 처리
}
}
}
앞의 파이프라인 예제와는 다르게 매개변수의 urls 채널이 받기 전용이 아닙니다. 왜냐하면 파이프라인 예제에서는 작업 요청을 다른 고루틴에서 보내주었지만 웹 크롤러에서는 crawl 함수에서 호출하는 parseFollowing 함수에서 URL을 만들어내기 때문입니다. 즉 worker 함수에서 crawl 함수로 URL을 처리하면서 동시에 다음 번에 처리할 URL을 생성하여 요청합니다. 따라서 보내기 및 받기를 모두 할 수 있도록 설정합니다.
select case를 사용하여 urls 채널에 값이 들어올 때마다 crawl 함수를 실행하거나 고루틴 채널이 닫히는지 확인합니다. 여기서 고루틴 정지 신호 채널 done이 닫히면 worker 함수를 빠져나옵니다. 예제에서는 case에서 바로 결괏값 채널에 값을 보냈지만 crawl 함수는 중복 URL은 처리하지 않고 넘어가므로 항상 결괏값이 나오지 않습니다. 따라서 default에서 매개변수로 결괏값 채널을 전달하는 방식으로 작성합니다.
먼저 팔로잉 정보와 사용자 정보를 구하는 parseFollowing 함수부터 알아보겠습니다.
func parseFollowing(doc *html.Node, urls chan string) <-chan string {
name := make(chan string)
go func() { // 교착 상태가 되지 않도록 고루틴으로 실행
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "img" { // img 태그
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "avatar left" {
// class가 avatar left인 요소
for _, a := range n.Attr {
if a.Key == "alt" {
name <- a.Val // 사용자 이름을 구한 뒤 채널에 보냄
break
}
}
}
if a.Key == "class" && a.Val == "gravatar" { // class가 gravatar인 요소
user := n.Parent.Attr[0].Val // 부모 요소의 첫 번째 속성(href)
// 사용자 이름으로 팔로잉 URL을 조합하여 urls 채널에 보냄
urls <- "https://github.com" + user + "/following"
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
}
f(doc)
}()
return name
}
HTML 정보를 탐색하는 로직은 앞과 같습니다. 하지만 여기서는 HTML 탐색 부분을 고루틴으로 만들었습니다. 이 부분을 고루틴으로 만든 이유는 두 가지가 있습니다.
- crawl, parseFollowing 함수도 worker 함수의 for url := range urls { } 안에서 실행되고 있으므로 urls 채널에 바로 값을 보내면 교착 상태가 됩니다. 그러므로 반드시 고루틴을 생성하여 채널에 값을 보내야 합니다.
- HTML 정보를 탐색하는 부분은 반복되는 부분이 많고, 나중에라도 로직이 복잡해질 수 있습니다. 따라서 처리 시간이 약간이나마 오래 걸릴 수 있으므로 고루틴으로 만들어서 worker 함수와는 별개로 실행합니다.
HTML 탐색 부분을 고루틴으로 실행했으므로 채널을 생성하여 사용자 이름을 리턴합니다.
func parseFollowing(doc *html.Node, urls chan string) <-chan string {
name := make(chan string)
... (생략)
if a.Key == "class" && a.Val == "avatar left" { // class가 avatar left인 요소
for _, a := range n.Attr {
if a.Key == "alt" {
// 사용자 이름을 구한 뒤 채널에 보냄
name <- a.Val
break
}
}
}
... (생략)
return name // 채널을 리턴
}
여기서는 팔로잉 URL을 슬라이스에 넣지 않고, urls 채널에 보냅니다. 이렇게 하면 worker 함수에서 URL을 가져가서 처리합니다.
... (생략)
if a.Key == "class" && a.Val == "gravatar" { // class가 gravatar인 요소
user := n.Parent.Attr[0].Val // 부모 요소의 첫 번째 속성(href)
// 사용자 이름으로 팔로잉 URL을 // 조합하여 urls 채널에 보냄
urls <- "https://github.com" + user + "/following"
break
}
... (생략)
이제 crawl 함수입니다.
...
func crawl(url string, urls chan string, c chan<- result) {
fetched.Lock() // 맵은 뮤텍스로 보호
if _, ok := fetched.m[url]; ok { // URL 중복 처리 여부를 검사
fetched.Unlock()
return
}
fetched.Unlock()
doc, err := fetch(url) // URL에서 파싱된 HTML 데이터를 가져옴
if err != nil { // URL을 가져오지 못했을 때
go func(u string) { // 교착 상태가 되지 않도록 고루틴을 생성
urls <- u // 채널에 URL을 보냄
}(url)
return
}
fetched.Lock()
fetched.m[url] = err // 가져온 URL은 맵에 URL과 에러 값 저장
fetched.Unlock()
name := <-parseFollowing(doc, urls) // 사용자 정보, 팔로잉 URL을 구함
c <- result{url, name} // 가져온 URL과 사용자 이름을 구조체 인스턴스로
// 생성하여 채널 c에 보냄
}
...
fetched 변수를 사용하여 중복 처리를 방지합니다. 그리고 fetch 함수로 URL을 가져오지 못했을 때는 urls 채널에 URL을 다시 보내줍니다. 여기서 crawl 함수는 worker 함수의 for url := range urls { } 안에서 실행되고 있으므로 교착 상태가 되지 않도록 고루틴을 생성하고 채널에 값을 보냅니다.
parseFollowing 함수가 리턴하는 채널에서 사용자 이름을 꺼낸 뒤 변수에 저장하고, 사용자 이름과 URL로 결괏값 구조체 인스턴스를 생성하여 채널 c에 보냅니다.
이제 메인 함수에서 urls 채널에 최초 URL을 보내고, 결괏값 채널에 값이 들어올 때까지 기다립니다.
...
func main() {
...
urls <- "https://github.com/pyrasis/following" // 최초 URL을 보냄
count := 0
for r := range c { // 결과 채널에 값이 들어올 때까지 대기한 뒤 값을 가져옴
fmt.Println(r.name)
count++
if count > 100 { // 100명만 출력한 뒤
close(done) // done을 닫아서 worker 고루틴을 종료
break
}
}
}
모든 GitHub 사용자를 수집하는 것이 목적이 아니므로 100명만 출력한 뒤 done 채널을 닫아서 worker 고루틴을 종료합니다.
다음은 전체 소스 코드입니다.
package main
import (
"fmt"
"golang.org/x/net/html" // HTML 파싱 해키지
"log"
"net/http"
"runtime"
"sync"
)
var fetched = struct {
m map[string]error // 중복 검사를 위한 URL과 에러 값 저장
sync.Mutex
}{m: make(map[string]error)} // 변수를 선언하면서 이름이 없는 구조체를 정의하고
// 초깃값을 생성하여 대입
type result struct { // 결괏값을 저장할 구조체
url string // 가져온 URL
name string // 사용자 이름
}
func fetch(url string) (*html.Node, error) {
res, err := http.Get(url) // URL에서 HTML 데이터를 가져옴
if err != nil {
log.Println(err)
return nil, err
}
doc, err := html.Parse(res.Body) // res.Body를 넣으면 파싱된 데이터가 리턴됨
if err != nil {
log.Println(err)
return nil, err
}
return doc, nil
}
func parseFollowing(doc *html.Node, urls chan string) <-chan string {
name := make(chan string)
go func() { // 교착 상태가 되지 않도록 고루틴으로 실행
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "img" { // img 태그
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "avatar left" {
// class가 avatar left인 요소
for _, a := range n.Attr {
if a.Key == "alt" {
// 사용자 이름을 구한 뒤 채널에 보냄
name <- a.Val
break
}
}
}
if a.Key == "class" && a.Val == "gravatar" { // class가 gravatar인 요소
user := n.Parent.Attr[0].Val // 부모 요소의 첫 번째 속성(href)
// 사용자 이름으로 팔로잉 URL을 조합하여 urls 채널에 보냄
urls <- "https://github.com" + user + "/following"
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
}
f(doc)
}()
return name // 채널을 리턴
}
func crawl(url string, urls chan string, c chan<- result) {
fetched.Lock() // 맵은 뮤텍스로 보호
if _, ok := fetched.m[url]; ok { // URL 중복 처리 여부를 검사
fetched.Unlock()
return
}
fetched.Unlock()
doc, err := fetch(url) // URL에서 파싱된 HTML 데이터를 가져옴
if err != nil { // URL을 가져오지 못했을 때
go func(u string) { // 교착 상태가 되지 않도록 고루틴을 생성
urls <- u // 채널에 URL을 보냄
}(url)
return
}
fetched.Lock()
fetched.m[url] = err // 가져온 URL은 맵에 URL과 에러 값 저장
fetched.Unlock()
name := <-parseFollowing(doc, urls) // 사용자 정보, 팔로잉 URL을 구함
c <- result{url, name} // 가져온 URL과 사용자 이름을 구조체 인스턴스로
// 생성하여 채널 c에 보냄
}
// 실제 작업을 처리하는 worker 함수
func worker(done <-chan struct{}, urls chan string, c chan<- result) {
for url := range urls { // urls 채널에서 URL을 가져옴
select {
case <-done: // 채널이 닫히면 worker 함수를 빠져나옴
return
default:
crawl(url, urls, c) // URL 처리
}
}
}
func main() {
numCPUs := runtime.NumCPU()
runtime.GOMAXPROCS(numCPUs) // 모든 CPU를 사용하도록 설정
urls := make(chan string) // 작업을 요청할 채널
done := make(chan struct{}) // 작업 고루틴에 정지 신호를 보낼 채널
c := make(chan result) // 결괏값을 저장할 채널
var wg sync.WaitGroup
const numWorkers = 10
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ { // 작업을 처리할 고루틴을 10개 생성
go func() {
worker(done, urls, c)
wg.Done()
}()
}
go func() {
wg.Wait() // 고루틴이 끝날 때까지 대기
close(c) // 대기가 끝나면 결괏값 채널을 닫음
}()
urls <- "https://github.com/pyrasis/following" // 최초 URL을 보냄
count := 0
for r := range c { // 결과 채널에 값이 들어올 때까지 대기한 뒤 값을 가져옴
fmt.Println(r.name)
count++
if count > 100 { // 100명만 출력한 뒤
close(done) // done을 닫아서 worker 고루틴을 종료
break
}
}
}
소스 코드를 컴파일하여 실행해보면 런타임 에러가 발생하지 않고 원활하게 데이터를 가져오는 것을 볼 수 있습니다.
이번 예제에서는 사용자 100명을 출력한 뒤 프로그램을 완전히 종료하므로 done 채널을 닫는 행동은 별로 의미가 없습니다. 하지만 URL을 처리하는 부분에서 특정 조건에 done 채널을 닫는다면 worker 고루틴을 모두 종료하면서 작업을 끝낼 수 있습니다.





저작권 안내
이 웹사이트에 게시된 모든 글의 무단 복제 및 도용을 금지합니다.- 블로그, 게시판 등에 퍼가는 것을 금지합니다.
- 비공개 포스트에 퍼가는 것을 금지합니다.
- 글 내용, 그림을 발췌 및 요약하는 것을 금지합니다.
- 링크 및 SNS 공유는 허용합니다.