- 책 또는 웹사이트의 내용을 복제하여 다른 곳에 게시하는 것을 금지합니다.
- 책 또는 웹사이트의 내용을 발췌, 요약하여 강의 자료, 발표 자료, 블로그 포스팅 등으로 만드는 것을 금지합니다.
실전 예제: 웹 크롤러 작성하기
이재홍 http://www.pyrasis.com 2014.12.17 ~ 2015.02.07
구조체와 인터페이스 활용하기
지금까지 GitHub 사용자의 팔로잉만 따라가면서 이름을 가져왔지만 이번에는 팔로잉한 사람의 별표 저장소(Stared)도 함께 가져와보겠습니다. 하지만 앞에서 함수만으로 구현한 웹 크롤러는 새로운 기능을 추가하기가 힘듭니다. 따라서 구조체와 인터페이스를 활용하여 웹 크롤러를 좀 더 확장해보겠습니다.
다음은 새로 구현할 웹 크롤러의 GitHub 팔로잉, 별표 구조체와 인터페이스간의 관계입니다.
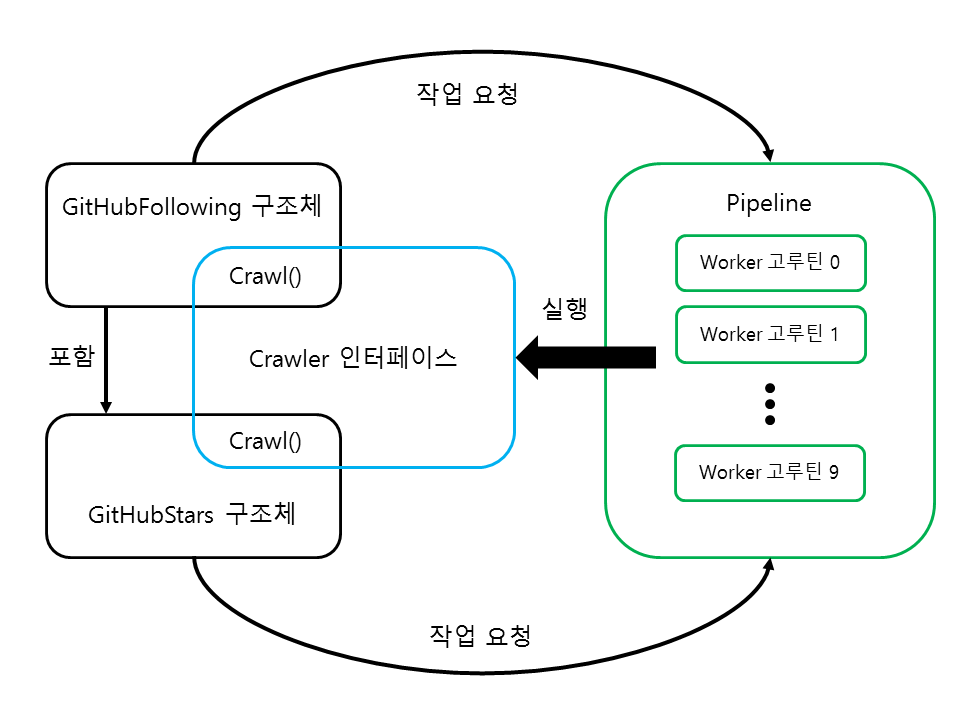 그림 66-4 웹 크롤러의 구조체와 인터페이스간의 관계
그림 66-4 웹 크롤러의 구조체와 인터페이스간의 관계
- GitHubFollowing 구조체와 메서드는 GitHub 사용자의 팔로잉 페이지를 처리합니다.
- 사용자 이름을 수집합니다.
- 팔로잉 URL과 별표 URL을 구합니다.
- 팔로잉 URL과 별표 URL을 처리하도록 파이프라인에 작업을 요청합니다.
- 별표 URL 처리 요청도 해야하므로 GitHubFollowing 구조체는 GitHubStars 구조체를 멤버로 포함하고 있습니다.
- GitHubStars 구조체와 메서드 GitHub 사용자의 별표 페이지를 처리합니다.
- 별표한 저장소 이름을 수집합니다.
- GitHubFollowing, GitHubStars 구조체 모두 Crawl 메서드를 구현하여 Crawler 인터페이스를 따릅니다.
- 파이프라인의 Worker 함수에서는 Crawler 인터페이스를 처리합니다.
팔로잉 페이지와 별표 페이지는 각각 GitHubFollowing, GitHubStars 구조체와 메서드로 구현하였습니다. 그리고 파이프라인의 Worker 함수에서는 두 구조체를 모두 처리할 수 있도록 Crawler 인터페이스를 활용합니다.
먼저 결괏값을 저장할 구조체를 정의합니다. 팔로잉 페이지에서는 URL과 사용자 이름을 저장하고, 별표 페이지에서는 저장소 이름만 저장하겠습니다.
package main
import (
"fmt"
"golang.org/x/net/html" // HTML 파싱 해키지
"log"
"net/http"
"runtime"
"sync"
)
// 팔로잉 결괏값을 저장할 구조체
type FollowingResult struct {
url string
name string
}
// 별표 저장소 결괏값을 저장할 구조체
type StarsResult struct {
repo string
}
...
중복 URL과 중복 저장소 이름을 처리할 구조체를 정의합니다. 여러 고루틴에서 맵에 접근하므로 sync.Mutex로 데이터를 보호해줍니다.
...
// 중복 URL을 처리할 구조체
type FetchedUrl struct {
m map[string]error
sync.Mutex
}
// 중복 저장소 이름을 처리할 구조체
type FetchedRepo struct {
m map[string]struct{}
sync.Mutex
}
...
FetchedRepo의 맵에는 특별히 데이터를 저장하지 않을 것이므로 map[string]struct{}처럼 값 부분을 빈 구조체로 정의합니다.
이제 Crawler 인터페이스를 정의합니다.
...
// Crawler 인터페이스 정의
type Crawler interface {
Crawl()
}
...
Crawler 인터페이스는 Crawl 메서드를 정의하고 있습니다. 따라서 어떤 구조체든 Crawl 메서드만 구현하면 Crawler 인터페이스로 처리될 수 있습니다. 이번 예제에서는 GitHubFollowing, GitHubStars 구조체가 Crawl 메서드를 구현합니다.
Crawler 인터페이스를 처리할 파이프라인 구조체를 정의합니다.
...
// Crawler 인터페이스를 처리할 파이프라인 구조체 정의
type Pipeline struct {
request chan Crawler // Crawler 타입으로 채널 선언
done chan struct{}
wg *sync.WaitGroup
}
...
Pipeline 구조체에는 Crawler 인터페이스로 작업 요청을 받을 수 있도록 Crawler 타입으로 request 채널을 정의합니다. 그리고 작업 고루틴에 정지 신호를 보낼 채널과 작업 고루틴의 실행이 끝날 때까지 기다릴 sync.WaitGroup를 멤버로 넣습니다.
이제 GitHubFollowing, GitHubStars 구조체를 정의합니다.
...
// 팔로잉 수집 구조체 정의
type GitHubFollowing struct {
fetchedUrl *FetchedUrl // 중복 URL을 처리할 멤버
p *Pipeline // 파이프라인에 작업 요청을 보낼 멤버
stars *GitHubStars // 별표 페이지도 처리해야 하므로 stars 멤버도 포함
result chan FollowingResult // 결괏값을 보낼 멤버
url string // URL 처리 작업을 요청하기 위한 멤버
}
// 별표 저장소 수집 구조체 정의
type GitHubStars struct {
fetchedUrl *FetchedUrl // 중복 URL을 처리할 멤버
fetchedRepo *FetchedRepo // 중복 저장소 이름을 처리할 멤버
p *Pipeline // 파이프라인에 작업 요청을 보낼 멤버
result chan StarsResult // 결괏값을 보낼 멤법
url string // URL 처리 작업을 요청하기 위한 멤버
}
...
GitHubFollowing 구조체는 중복 URL을 처리할 FetchedUrl, 파이프라인에 작업 요청을 보낼 Pipeline, 결괏값을 보낼 FollowingResult 채널을 멤버로 가지고 있습니다. 그리고 팔로잉 페이지에서 별표 페이지의 URL 생성하여 파이프라인에 작업을 요청해야 하므로 GitHubStars도 멤버로 가지고 있습니다. 마지막으로 파이프라인에 URL 처리 작업을 요청하기 위해 url 멤버를 넣습니다.
여기서 주의할 점은 fetchedUrl, p, stars는 포인터이며 유일한 인스턴스입니다. 마찬가지로 result 채널도 유일합니다. 파이프라인에 작업 요청을 보낼 때 GitHubFollowing 구조체 자체를 새로 생성하여 채널에 보낼 것이므로 url 값만 새로 생성하면 됩니다. 따라서 나머지 fetchedUrl, p, stars, result는 기존의 포인터를 그대로 사용합니다.
GitHubStars 구조체는 중복 URL을 처리할 FetchedUrl, 중복 저장소 이름를 처리할 FetchedRepo, 파이프라인에 작업 요청을 보낼 Pipeline, 결괏값을 보낼 StarsResult 채널을 멤버로 가지고 있습니다. 마지막으로 파이프라인에 URL 처리 작업을 요청하기 위해 url 멤버를 가지고 있습니다. GitHubStars 구조체도 포인터 값이 유일한 점은 GitHubFollowing 구조체와 같습니다.
다음과 같이 팔로잉, 별표 URL 처리 작업을 요청하는 함수를 만듭니다.
...
func (g *GitHubFollowing) Request(url string) {
g.p.request <- &GitHubFollowing{ // 구조체를 생성하여 파이프라인의 request 채널에 보냄
fetchedUrl: g.fetchedUrl, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
p: g.p, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
result: g.result, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
stars: g.stars, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
url: url, // url만 새로운 값
}
}
func (g *GitHubStars) Request(url string) {
g.p.request <- &GitHubStars{ // 구조체를 생성하여 파이프라인의 request 채널에 보냄
fetchedUrl: g.fetchedUrl, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
fetchedRepo: g.fetchedRepo, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
p: g.p, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
result: g.result, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
url: url, // url만 새로운 값
}
}
...
g.p.request <- &GitHubFollowing{ }처럼 구조체 인스턴스를 생성하여 파이프라인 포인터의 request 채널에 보냅니다. 여기서 매개변수로 받은 url만 새로운 값이고, 나머지는 현재 인스턴스 g에서 포인터를 가져와서 다시 구조체에 채워넣습니다. 즉 전역변수를 사용하지 않고, 포인터를 활용하여 구조체 안에서 유일 인스턴스를 계속 가지고다니는 방법입니다.
다음은 팔로잉 페이지에서 사용자 이름, 팔로잉 URL, 별표 URL을 구하는 Parse 메서드입니다.
...
// 팔로잉 페이지에서 사용자 이름, 팔로잉 URL, 별표 URL을 구함
func (g *GitHubFollowing) Parse(doc *html.Node) <-chan string {
name := make(chan string)
go func() {
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "img" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "avatar left" {
// class가 avatar left인 요소
for _, a := range n.Attr {
if a.Key == "alt" {
name <- a.Val // 사용자 이름을 구한 뒤 채널에 보냄
break
}
}
}
if a.Key == "class" && a.Val == "gravatar" {
// 부모 요소의 첫 번째 속성(href)
user := n.Parent.Attr[0].Val
// 팔로잉 URL을 파이프라인에 보냄
g.Request("https://github.com" + user + "/following")
// 별표 URL을 파이프라인에 보냄
g.stars.Request("https://github.com/stars" + user)
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
}
f(doc)
}()
return name
}
...
사용자 이름을 구하여 채널에 보내고, 팔로잉 URL과 별표 URL을 앞에서 만든 Request 메서드로 파이프라인에 보냅니다. 여기서 팔로잉 URL은 g.Request처럼 GitHubFollowing 구조체의 Request 메서드를 사용하고, 별표 URL은 g.stars.Request처럼 GitHubFollowing 구조체안에 저장된 stars 포인터의 Request 메서드를 사용합니다. 즉 어떤 구조체 인스턴스를 생성하여 파이프라인의 채널에 보내느냐에 따라 호출되는 HTML 처리 메서드(Crawl)가 달라집니다.
GitHubFollowing 구조체가 Crawler 인터페이스로 처리될 수 있도록 Crawl 메서드를 구현합니다.
...
func (g *GitHubFollowing) Crawl() {
g.fetchedUrl.Lock() // 맵은 뮤텍스로 보호
if _, ok := g.fetchedUrl.m[g.url]; ok { // URL 중복 처리 여부를 검사
g.fetchedUrl.Unlock()
return
}
g.fetchedUrl.Unlock()
doc, err := fetch(g.url) // URL에서 파싱된 HTML 데이터를 가져옴
if err != nil { // URL을 가져오지 못했을 때
go func(u string) { // 교착 상태가 되지 않도록 고루틴을 생성
g.Request(u) // 파이프라인에 URL을 보냄
}(g.url)
return
}
g.fetchedUrl.Lock()
g.fetchedUrl.m[g.url] = err // 가져온 URL은 맵에 URL과 에러 값 저장
g.fetchedUrl.Unlock()
name := <-g.Parse(doc) // 사용자 이름을 구함
g.result <- FollowingResult{g.url, name} // 사용자 이름과 URL을 팔로잉 결과 채널에 보냄
}
...
fetchedUrl 포인터로 URL 중복 처리를 방지합니다. 그리고 fetch 함수로 URL을 가져오지 못했을 때는 Request 메서드로 URL 처리를 다시 요청합니다.
Parse 메서드가 리턴하는 채널에서 사용자 이름을 꺼낸 뒤 변수에 저장하고, 사용자 이름과 URL로 FollowingResult 구조체 인스턴스를 생성하여 result 채널에 보냅니다.
다음은 별표 페이지에서 저장소 이름을 구하는 Parse 메서드입니다.
...
// 별표 페이지에서 저장소 이름을 구함
func (g *GitHubStars) Parse(doc *html.Node) <-chan string {
repo := make(chan string)
go func() {
defer close(repo) // 고루틴이 끝나기 직전에 채널을 닫음
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" { // span 태그
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "prefix" { // class가 prefix인 요소
repo <- n.Parent.Attr[0].Val // 저장소 이름을 구한 뒤 채널에 보냄
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
}
f(doc)
}()
return repo
}
...
먼저 저장소 이름을 구하기 전에 별표 페이지의 HTML 구조를 살펴봅니다. 다음은 별표 페이지의 HTML 일부입니다.
... (생략)
<h3 class="repo-list-name">
<a href="/donald/webcrawler">
<span class="prefix">donald</span>
<span class="slash">/</span>
crawler
</a>
</h3>
... (생략)
우리가 구하고자 하는 저장소 이름(/사용자/저장소 형식)을 가지고 있는 <a> 태그에는 클래스 속성이 없습니다. 따라서 그 아래에 있는 <span> 태그의 prefix 클래스를 찾은 뒤 부모의 href 속성을 가져옵니다.
if n.Type == html.ElementNode && n.Data == "span" { // span 태그
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "prefix" { // class가 prefix인 요소
repo <- n.Parent.Attr[0].Val // 저장소 이름을 구한 뒤 채널에 보냄
break
}
}
}
n.Parent.Attr[0].Val처럼 <a> 태그의 href 속성을 가져온 뒤 repo 채널에 보냅니다.
여기서 주의할 점은 팔로잉 페이지의 사용자 이름은 하나 밖에 없지만 별표한 저장소는 보통 여러 개가 있다는 것입니다. 따라서 채널을 받는 쪽에서는 <-채널로 한 번만 꺼내지 않고 range 키워드로 여러 번 꺼내야 합니다. 다음과 같이 range 키워드로 값을 모두 꺼낸 뒤 대기하지 않도록 close 함수로 채널을 닫아줍니다.
func (g *GitHubStars) Parse(doc *html.Node) <-chan string {
repo := make(chan string)
go func() {
defer close(repo) // 고루틴이 끝나기 직전에 채널을 닫음
... (생략)
}()
return repo
}
defer close(repo)처럼 고루틴이 끝날 때 채널을 닫도록 지연 호출을 사용해도 되고, 고루틴 마지막에서 그냥 close 함수를 호출해도 됩니다.
GitHubFollowing 구조체도 Crawler 인터페이스로 처리될 수 있도록 Crawl 메서드를 구현합니다.
...
func (g *GitHubStars) Crawl() {
g.fetchedUrl.Lock() // 맵은 뮤텍스로 보호
if _, ok := g.fetchedUrl.m[g.url]; ok { // URL 중복 처리 여부를 검사
g.fetchedUrl.Unlock()
return
}
g.fetchedUrl.Unlock()
doc, err := fetch(g.url) // URL에서 파싱된 HTML 데이터를 가져옴
if err != nil { // URL을 가져오지 못했을 때
go func(u string) { // 교착 상태가 되지 않도록 고루틴을 생성
g.Request(u) // 파이프라인에 URL을 보냄
}(g.url)
return
}
g.fetchedUrl.Lock()
g.fetchedUrl.m[g.url] = err // 가져온 URL은 맵에 URL과 에러 값 저장
g.fetchedUrl.Unlock()
repositories := g.Parse(doc)
for r := range repositories { // 채널에서 range로 저장소 이름을 계속 꺼냄
g.fetchedRepo.Lock() // 맵은 뮤텍스로 보호
if _, ok := g.fetchedRepo.m[r]; !ok { // 저장소 중복 저장 여부 검사
g.result <- StarsResult{r} // 저장소 이름을 별표 저장소 결과 채널에 보냄
g.fetchedRepo.m[r] = struct{}{} // 저장한 저장소 이름은 맵에 저장
}
g.fetchedRepo.Unlock()
}
}
...
fetchedUrl 포인터로 URL 중복 처리를 방지합니다. 그리고 fetch 함수로 URL을 가져오지 못했을 때는 Request 메서드로 URL 처리를 다시 요청합니다.
Parse 메서드가 리턴하는 채널에서 for range 반복문으로 값을 계속 꺼냅니다. 그리고 fetchedRepo 포인터로 저장소를 중복 수집하지 않도록 한 뒤 StarsResult 구조체 인스턴스를 생성하여 result 채널에 보냅니다. 그리고 앞의 Parse 메서드에서 저장소 이름을 다 구했을 때 채널을 닫도록 했으므로 값이 없으면 대기하지 않고 range 루프를 빠져나옵니다.
fetchedUrl 포인터와 마찬가지로 fetchedRepo 포인터의 맵도 동시에 여러 고루틴에서 접근하므로 뮤텍스 함수로 보호해줍니다.
이제 파이프라인으로 돌아와서 파이프라인을 구현합니다. 다음은 파이프라인을 생성하는 함수입니다.
...
func NewPipeline() *Pipeline {
return &Pipeline{ // 새 파이프라인 생성
request: make(chan Crawler),
done: make(chan struct{}),
wg: new(sync.WaitGroup),
}
}
...
Pipeline 구조체 인스턴스를 생성한 뒤 포인터를 리턴하며 채널은 make 함수로 sync.WaitGroup는 new 함수로 생성합니다.
Run 함수에서는 작업을 처리할 고루틴을 10개 생성하고, sync.WaitGroup을 사용하여 고루틴이 끝날 때까지 대기합니다.
...
func (p *Pipeline) Run() {
const numWorkers = 10
p.wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ { // 작업을 처리할 고루틴 10개 생성
go func() {
p.Worker()
p.wg.Done()
}()
}
go func() {
p.wg.Wait() // 작업 고루틴이 끝날 때까지 대기
}()
}
...
실제 작업을 처리하는 worker 함수에서는 for range 반복문으로 request 채널에서 Crawler 인터페이스를 가져와서 처리합니다.
...
// 실제 작업을 처리하는 worker 함수
func (p *Pipeline) Worker() {
for r := range p.request { // request 채널에서 Crawler 인터페이스를 가져옴
select {
case <-p.done: // 채널이 닫히면 worker 함수를 빠져나옴
return
default:
r.Crawl() // Crawler 인터페이스의 Crawl 함수 실행
}
}
}
...
이렇게하면 어떤 구조체든 상관없이 Crawler 인터페이스로 간단하게 처리할 수 있습니다.
이제 main 함수에서 파이프라인과 GitHubFollowing, GitHubStars 구조체로 초기 인스턴스를 생성합니다.
...
func main() {
...
p := NewPipeline() // 파이프라인 인스턴스 생성
p.Run() // worker 함수를 고루틴으로 생성
stars := &GitHubStars{ // 별표 구조체 인스턴스 생성
fetchedUrl: &FetchedUrl{m: make(map[string]error)}, // 중복 URL 처리 맵
fetchedRepo: &FetchedRepo{m: make(map[string]struct{})}, // 중복 저장소
// 이름 처리 맵
p: p, // 파이프라인 인스턴스
result: make(chan StarsResult), // 별표 저장소
// 결괏값 채널
}
following := &GitHubFollowing{ // 팔로잉 구조체 인스턴스 생성
fetchedUrl: &FetchedUrl{m: make(map[string]error)}, // 중복 URL 처리 맵
p: p, // 파이프라인 인스턴스
result: make(chan FollowingResult), // 팔로잉 결괏값 채널
stars: stars, // GitHubStars 구조체 인스턴스
url: "https://github.com/pyrasis/following", // 최초 시작 URL
}
p.request <- following // 파이프라인에 구조체 인스턴스를 보내서 HTML 처리 작업 시작
...
NewPipeline 함수로 파이프라인 인스턴스를 생성한 뒤 Run 함수로 Worker 함수들을 고루틴으로 실행합니다.
GitHubStars 구조체에는 FetchedUrl, FetchedRepo 구조체 인스턴스를 생성하여 레퍼런스(포인터)를 넣어주고, 파이프라인 포인터와 StarsResult 채널을 생성하여 넣어줍니다. 그리고 GitHubFollowing 구조체에는 FetchedUrl 포인터, 파이프라인 포인터, 앞에서 생성한 GitHubStars 구조체 인스턴스의 포인터를 넣어주고, FollowingResult 채널을 생성하여 넣어줍니다. 마지막으로 url에는 최초 시작 URL을 넣습니다.
구조체 인스턴스를 모두 생성했다면 파이프라인의 request 채널에 보내서 HTML 처리 작업을 시작합니다.
각종 초기화가 끝났으면 다음과 같이 결괏값을 받아서 출력합니다.
...
func main() {
...
count := 0
LOOP:
for { // 무한 루프 사용
select { // 채널에 결괏값이 들어왔을 때마다 값을 출력
case f := <-following.result:
fmt.Println(f.name)
case s := <-stars.result:
fmt.Println(s.repo)
if count == 1000 { // 저장소를 1,000개만 출력
close(p.done) // done 채널을 닫음
break LOOP // 무한 루프를 빠져나옴
}
count++
}
}
}
for 무한루프에서 select case를 사용하여 following.result, stars.result 채널에 결과가 들어왔을 때마다 값을 출력합니다. 여기서는 저장소 개수를 1,000개만 출력한 뒤 done 채널을 닫아서 파이프라인의 Worker 고루틴을 종료합니다. select case에서 break를 사용하면 select만 빠져나가므로 for 반복문을 완전히 빠져나가기 위해 break에 레이블(LOOP)을 지정하여 빠져나옵니다.
앞의 예제와 마찬가지로 여기서도 URL을 처리하는 부분에서 특정 조건에 done 채널을 닫는다면 worker 고루틴을 모두 종료하면서 작업을 끝낼 수 있습니다.
다음은 전체 소스 코드입니다.
package main
import (
"fmt"
"golang.org/x/net/html" // HTML 파싱 해키지
"log"
"net/http"
"runtime"
"sync"
)
// 팔로잉 결괏값을 저장할 구조체
type FollowingResult struct {
url string
name string
}
// 별표 저장소 결괏값을 저장할 구조체
type StarsResult struct {
repo string
}
// 중복 URL을 처리할 구조체
type FetchedUrl struct {
m map[string]error
sync.Mutex
}
// 중복 저장소 이름을 처리할 구조체
type FetchedRepo struct {
m map[string]struct{}
sync.Mutex
}
// Crawler 인터페이스 정의
type Crawler interface {
Crawl()
}
// 팔로잉 수집 구조체 정의
type GitHubFollowing struct {
fetchedUrl *FetchedUrl // 중복 URL을 처리할 멤버
p *Pipeline // 파이프라인에 작업 요청을 보낼 멤버
stars *GitHubStars // 별표 페이지도 처리해야 하므로 stars 멤버도 포함
result chan FollowingResult // 결괏값을 보낼 멤버
url string // URL 처리 작업을 요청하기 위한 멤버
}
// 별표 저장소 수집 구조체 정의
type GitHubStars struct {
fetchedUrl *FetchedUrl // 중복 URL을 처리할 멤버
fetchedRepo *FetchedRepo // 중복 저장소 이름을 처리할 멤버
p *Pipeline // 파이프라인에 작업 요청을 보낼 멤버
result chan StarsResult // 결괏값을 보낼 멤법
url string // URL 처리 작업을 요청하기 위한 멤버
}
func fetch(url string) (*html.Node, error) {
res, err := http.Get(url)
if err != nil {
log.Println(err)
return nil, err
}
doc, err := html.Parse(res.Body)
if err != nil {
log.Println(err)
return nil, err
}
return doc, nil
}
func (g *GitHubFollowing) Request(url string) {
g.p.request <- &GitHubFollowing{ // 구조체를 생성하여 파이프라인의 request 채널에 보냄
fetchedUrl: g.fetchedUrl, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
p: g.p, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
result: g.result, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
stars: g.stars, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
url: url, // url만 새로운 값
}
}
// 팔로잉 페이지에서 사용자 이름, 팔로잉 URL, 별표 URL을 구함
func (g *GitHubFollowing) Parse(doc *html.Node) <-chan string {
name := make(chan string)
go func() {
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "img" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "avatar left" {
// class가 avatar left인 요소
for _, a := range n.Attr {
if a.Key == "alt" {
// 사용자 이름을 구한 뒤 채널에 보냄
name <- a.Val
break
}
}
}
if a.Key == "class" && a.Val == "gravatar" {
// 부모 요소의 첫 번째 속성(href)
user := n.Parent.Attr[0].Val
// 팔로잉 URL을 파이프라인에 보냄
g.Request("https://github.com" + user + "/following")
// 별표 URL을 파이프라인에 보냄
g.stars.Request("https://github.com/stars" + user)
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
}
f(doc)
}()
return name
}
func (g *GitHubFollowing) Crawl() {
g.fetchedUrl.Lock() // 맵은 뮤텍스로 보호
if _, ok := g.fetchedUrl.m[g.url]; ok { // URL 중복 처리 여부를 검사
g.fetchedUrl.Unlock()
return
}
g.fetchedUrl.Unlock()
doc, err := fetch(g.url) // URL에서 파싱된 HTML 데이터를 가져옴
if err != nil { // URL을 가져오지 못했을 때
go func(u string) { // 교착 상태가 되지 않도록 고루틴을 생성
g.Request(u) // 파이프라인에 URL을 보냄
}(g.url)
return
}
g.fetchedUrl.Lock()
g.fetchedUrl.m[g.url] = err // 가져온 URL은 맵에 URL과 에러 값 저장
g.fetchedUrl.Unlock()
name := <-g.Parse(doc) // 사용자 이름을 구함
g.result <- FollowingResult{g.url, name} // 사용자 이름과 URL을 팔로잉 결과 채널에 보냄
}
func (g *GitHubStars) Request(url string) {
g.p.request <- &GitHubStars{ // 구조체를 생성하여 파이프라인의 request 채널에 보냄
fetchedUrl: g.fetchedUrl, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
fetchedRepo: g.fetchedRepo, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
p: g.p, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
result: g.result, // 현재 인스턴스에서 포인터를 가져와서 다시 사용
url: url, // url만 새로운 값
}
}
// 별표 페이지에서 저장소 이름을 구함
func (g *GitHubStars) Parse(doc *html.Node) <-chan string {
repo := make(chan string)
go func() {
defer close(repo) // 고루틴이 끝나기 직전에 채널을 닫음
var f func(*html.Node)
f = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" { // span 태그
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "prefix" { // class가 prefix인 요소
// 저장소 이름을 구한 뒤 채널에 보냄
repo <- n.Parent.Attr[0].Val
break
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
f(c) // 재귀호출로 자식과 형제를 모두 탐색
}
}
f(doc)
}()
return repo
}
func (g *GitHubStars) Crawl() {
g.fetchedUrl.Lock() // 맵은 뮤텍스로 보호
if _, ok := g.fetchedUrl.m[g.url]; ok { // URL 중복 처리 여부를 검사
g.fetchedUrl.Unlock()
return
}
g.fetchedUrl.Unlock()
doc, err := fetch(g.url) // URL에서 파싱된 HTML 데이터를 가져옴
if err != nil { // URL을 가져오지 못했을 때
go func(u string) { // 교착 상태가 되지 않도록 고루틴을 생성
g.Request(u) // 파이프라인에 URL을 보냄
}(g.url)
return
}
g.fetchedUrl.Lock()
g.fetchedUrl.m[g.url] = err // 가져온 URL은 맵에 URL과 에러 값 저장
g.fetchedUrl.Unlock()
repositories := g.Parse(doc)
for r := range repositories { // 채널에서 range로 저장소 이름을 계속 꺼냄
g.fetchedRepo.Lock() // 맵은 뮤텍스로 보호
if _, ok := g.fetchedRepo.m[r]; !ok { // 저장소 중복 저장 여부 검사
g.result <- StarsResult{r} // 저장소 이름을 별표 저장소 결과 채널에 보냄
g.fetchedRepo.m[r] = struct{}{} // 저장한 저장소 이름은 맵에 저장
}
g.fetchedRepo.Unlock()
}
}
// Crawler 인터페이스를 처리할 파이프라인 구조체 정의
type Pipeline struct {
request chan Crawler // Crawler 타입으로 채널 선언
done chan struct{}
wg *sync.WaitGroup
}
func NewPipeline() *Pipeline {
return &Pipeline{ // 새 파이프라인 생성
request: make(chan Crawler),
done: make(chan struct{}),
wg: new(sync.WaitGroup),
}
}
// 실제 작업을 처리하는 worker 함수
func (p *Pipeline) Worker() {
for r := range p.request { // request 채널에서 Crawler 인터페이스를 가져옴
select {
case <-p.done: // 채널이 닫히면 worker 함수를 빠져나옴
return
default:
r.Crawl() // Crawler 인터페이스의 Crawl 함수 실행
}
}
}
func (p *Pipeline) Run() {
const numWorkers = 10
p.wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ { // 작업을 처리할 고루틴 10개 생성
go func() {
p.Worker()
p.wg.Done()
}()
}
go func() {
p.wg.Wait() // 작업 고루틴이 끝날 때까지 대기
}()
}
func main() {
numCPUs := runtime.NumCPU()
runtime.GOMAXPROCS(numCPUs) // 모든 CPU를 사용하도록 설정
p := NewPipeline() // 파이프라인 인스턴스 생성
p.Run() // worker 함수를 고루틴으로 생성
stars := &GitHubStars{ // 별표 구조체 인스턴스 생성
fetchedUrl: &FetchedUrl{m: make(map[string]error)}, // 중복 URL 처리 맵
fetchedRepo: &FetchedRepo{m: make(map[string]struct{})}, // 중복 저장소
// 이름 처리 맵
p: p, // 파이프라인 인스턴스
result: make(chan StarsResult), // 별표 저장소
// 결괏값 채널
}
following := &GitHubFollowing{ // 팔로잉 구조체 인스턴스 생성
fetchedUrl: &FetchedUrl{m: make(map[string]error)}, // 중복 URL 처리 맵
p: p, // 파이프라인 인스턴스
result: make(chan FollowingResult), // 팔로잉 결괏값 채널
stars: stars, // GitHubStars 구조체 인스턴스
url: "https://github.com/pyrasis/following", // 최초 시작 URL
}
p.request <- following // 파이프라인에 구조체 인스턴스를 보내서 HTML 처리 작업 시작
count := 0
LOOP:
for { // 무한 루프 사용
select { // 채널에 결괏값이 들어왔을 때마다 값을 출력
case f := <-following.result:
fmt.Println(f.name)
case s := <-stars.result:
fmt.Println(s.repo)
if count == 1000 { // 저장소를 1,000개만 출력
close(p.done) // done 채널을 닫음
break LOOP // 무한 루프를 빠져나옴
}
count++
}
}
}
소스 코드를 컴파일하여 실행해보면 GitHub 사용자 이름과 별표한 저장소 이름이 출력됩니다.
웹 크롤러로 과도하게 트래픽을 발생시키면 해당 사이트에서 IP 주소를 차단당할 수 있습니다. 따라서 반복적으로 무리하게 웹 사이트의 정보를 수집하지 않도록 합니다.





저작권 안내
이 웹사이트에 게시된 모든 글의 무단 복제 및 도용을 금지합니다.- 블로그, 게시판 등에 퍼가는 것을 금지합니다.
- 비공개 포스트에 퍼가는 것을 금지합니다.
- 글 내용, 그림을 발췌 및 요약하는 것을 금지합니다.
- 링크 및 SNS 공유는 허용합니다.